Tutorial
Base de Datos Normalizada para Consultar los Archivos I90 de REE
Construye una base de datos normalizada para consultar y analizar eficientemente datos históricos de programación energética del sistema eléctrico español. Aprende diseño de bases de datos, normalización y optimización para análisis del mercado energético.
Imagina que eres un trader energético y quieres analizar la gestión energética de las unidades más importantes del mercado eléctrico español, aquellas que han sufrido mayor curtailment. Lo ideal sería tener la información histórica de las unidades de programación energética en una base de datos (DB) para poder consultarla y analizarla de manera eficiente.
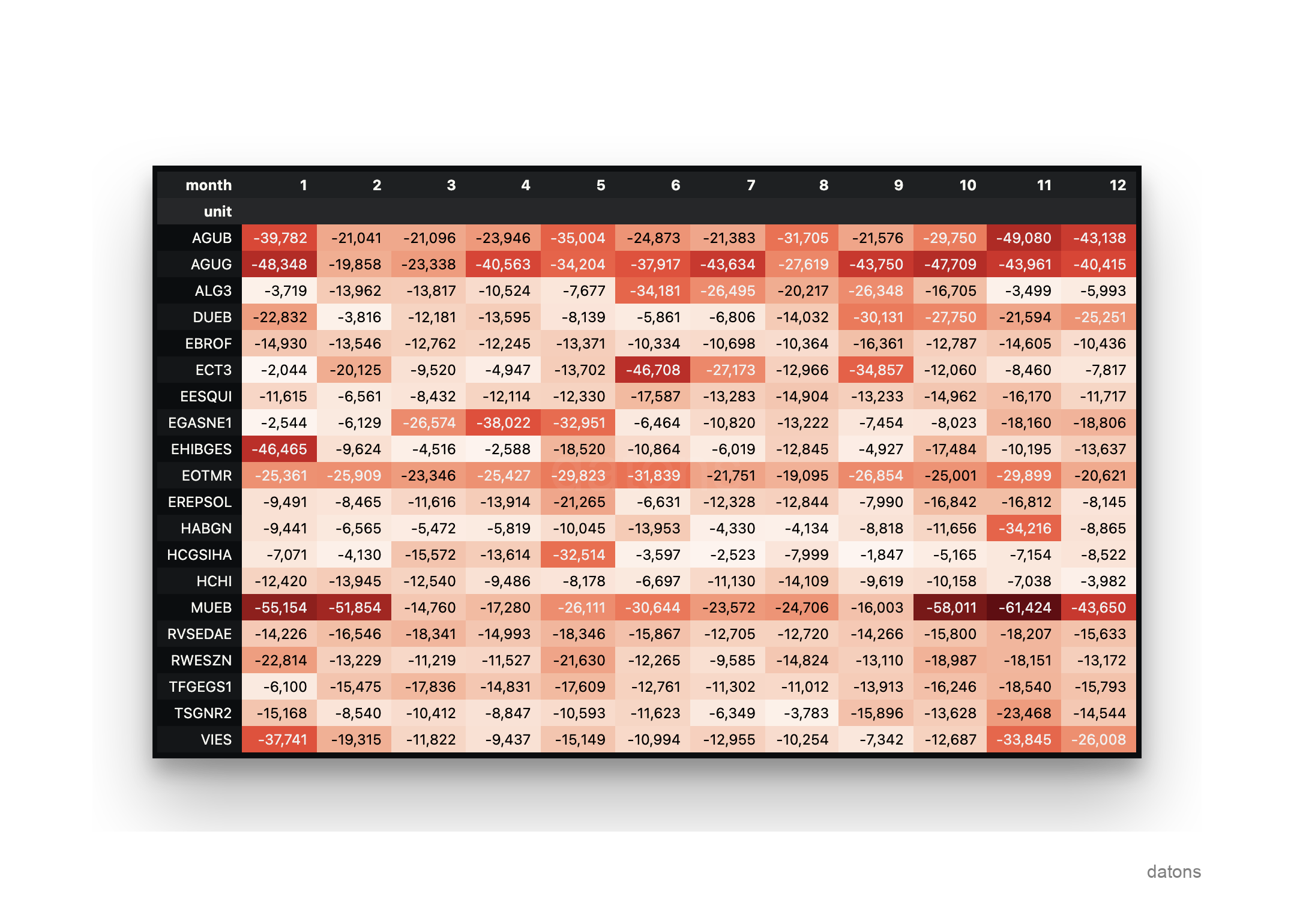
Por ejemplo, te gustaría consultar cuáles han sido las 5 unidades que han sufrido mayor curtailment tras el diario en cada mes del año 2023. Primero, descargas la información operativa desde una base de datos y luego la analizas.
from sqlalchemy import create_engine
import pandas as pd
engine = create_engine(f'postgresql://{USER}:{PASSWORD}@{URL}:{PORT}/{DATABASENAME}')
df = pd.read_sql_table(query, engine)
idx = df.groupby('unit').energy.sum().nsmallest(20).index
(df
.query('unit in @idx')
.pivot_table(
index='unit',
columns='month',
values='energy',
aggfunc='sum'
)
)
¿Por qué necesitas una base de datos para analizar la información de los archivos I90? Te lo explicamos a continuación.
Contexto archivos I90
Introducción
Como se explicó en el tutorial de Automatizaciones de Excel, los archivos I90 de REE proporcionan la información diaria de las unidades de programación energética en España según los programas de generación.
Limitaciones de los servidores públicos
Para trabajar con toda la información histórica, vamos a descargar todos los archivos I90 de REE a través de su web, desde la primera fecha disponible hasta la fecha actual. Una vez resuelta la búsqueda, clicamos sobre el fichero I90 para descargar el zip.
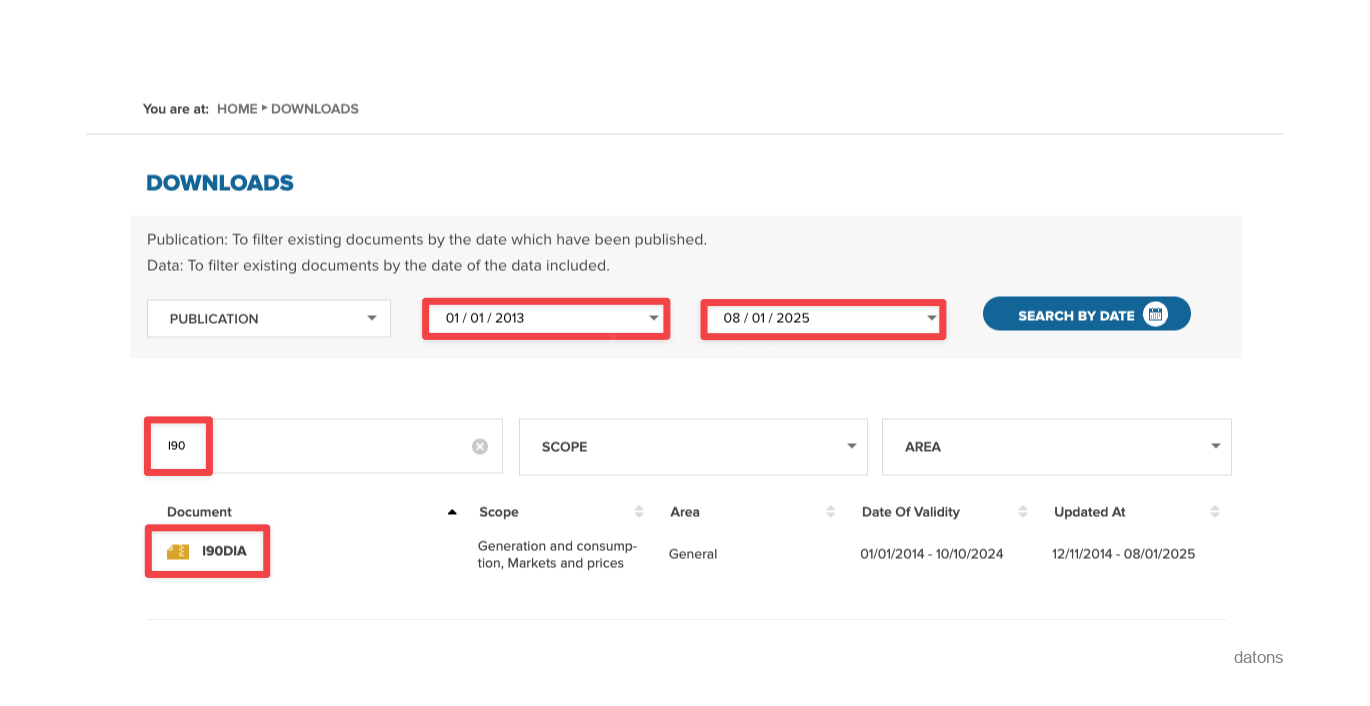
El primer fallo lo encontramos al solicitar un periodo tan amplio de datos; los servidores no soportan la cantidad de datos a enviar y se caen, mostrando un error.
{
"Status": 500,
"message": "Internal server error"
}Para cada día, REE debería devolver un zip con tantos Excels como días haya en el periodo solicitado.
Si además, tenemos que filtrar la información por sujetos de mercado entre todos los Excels, no solo tendríamos que descargar los datos, sino que deberíamos filtrarlos sobre cada Excel.
En cambio, si desarrollamos una base de datos para almacenar la información de manera estructurada en una sola tabla donde categorizamos los datos por sujetos de mercado, unidades de programación, programas de generación y tipo de resultado, podríamos consultar la información de manera mucho más eficiente.
Por ejemplo, si solicitamos toda la información operativa de las unidades de Iberdrola con código IBEG, tardaríamos menos de dos segundos.
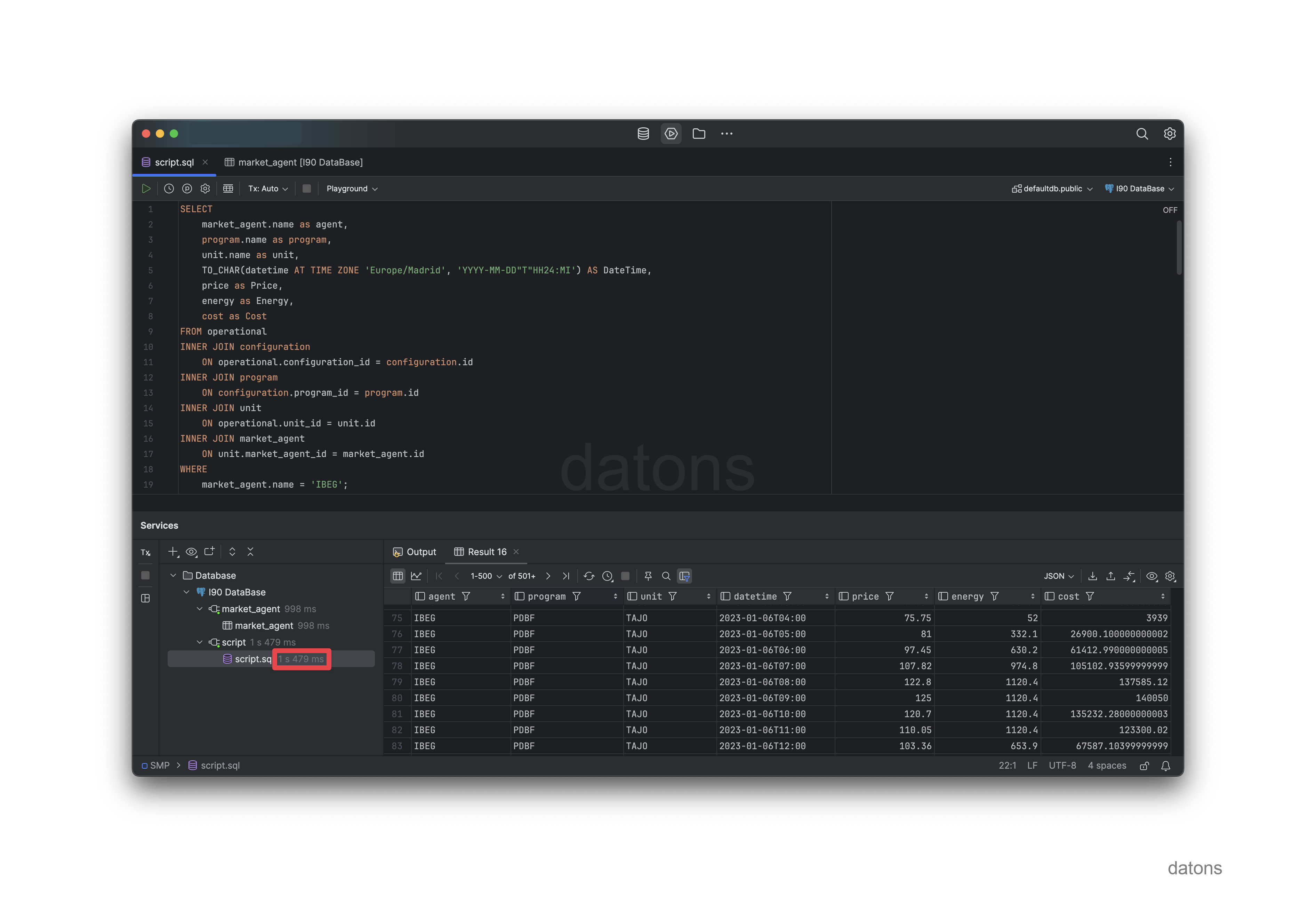
Empleamos más tiempo en preprocesar los Excel por cada nuevo análisis que en desarrollar la base de datos y volcar la información más actualizada cada día.
Proceso para desarrollar sistema de DB
Normalizar estructura de datos
Hay muchos Excels, cada uno con columnas similares pero no idénticas. Además, los valores son a veces en MWh y otras en €/MWh. Los datos I90 de REE son de unidades de generación, cada hoja representando un programa y tipo de resultado distinto.
La información del Excel no está normalizada. Es decir, los registros no están en una única tabla diferenciados por columnas que clasifiquen las observaciones. En su lugar, los registros se encuentran en diferentes hojas según programa y tipo de resultado. Por ejemplo, la hoja I90DIA03 solo contiene el resultado de la resolución de restricciones en el mercado diario, en MWh.
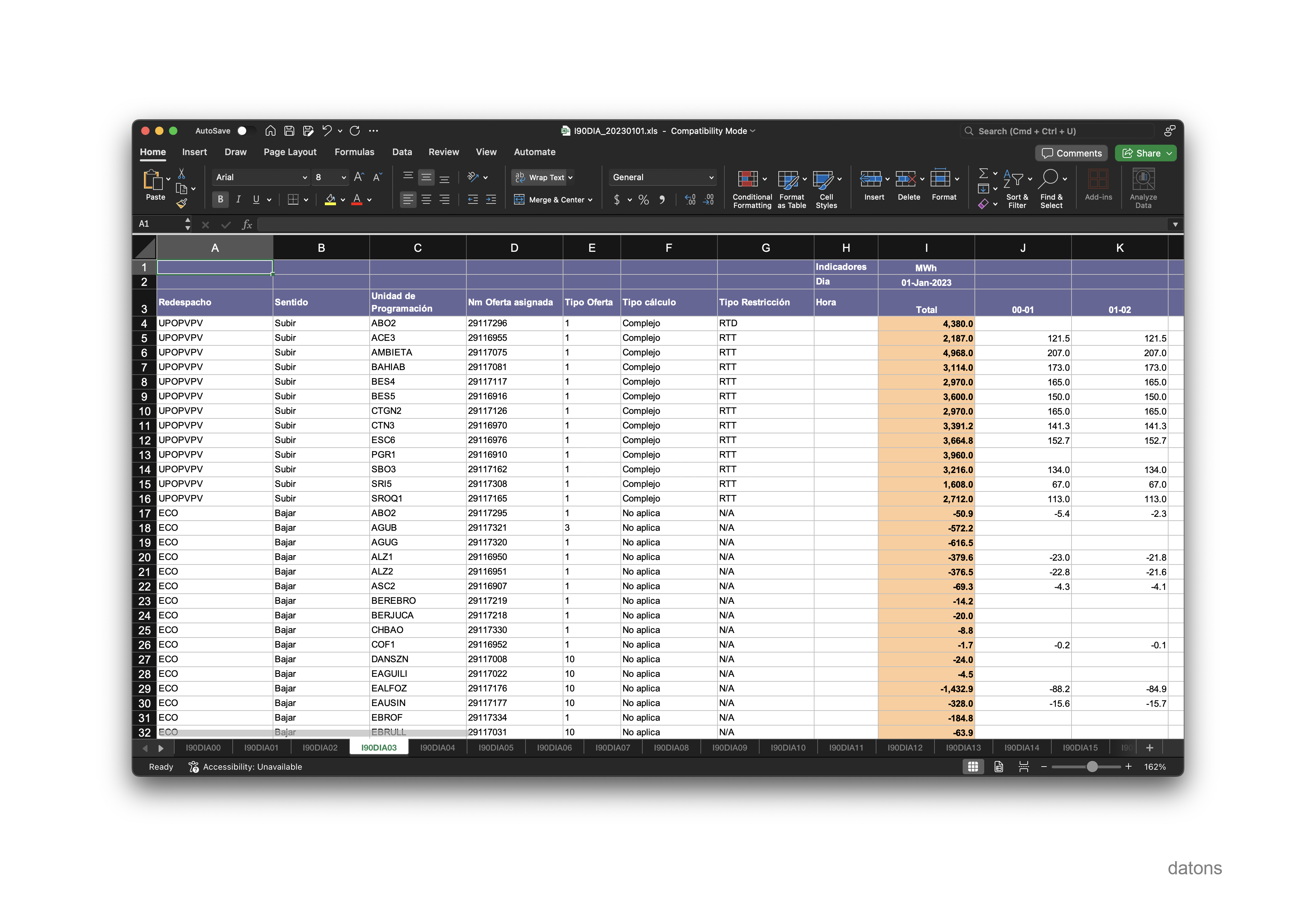
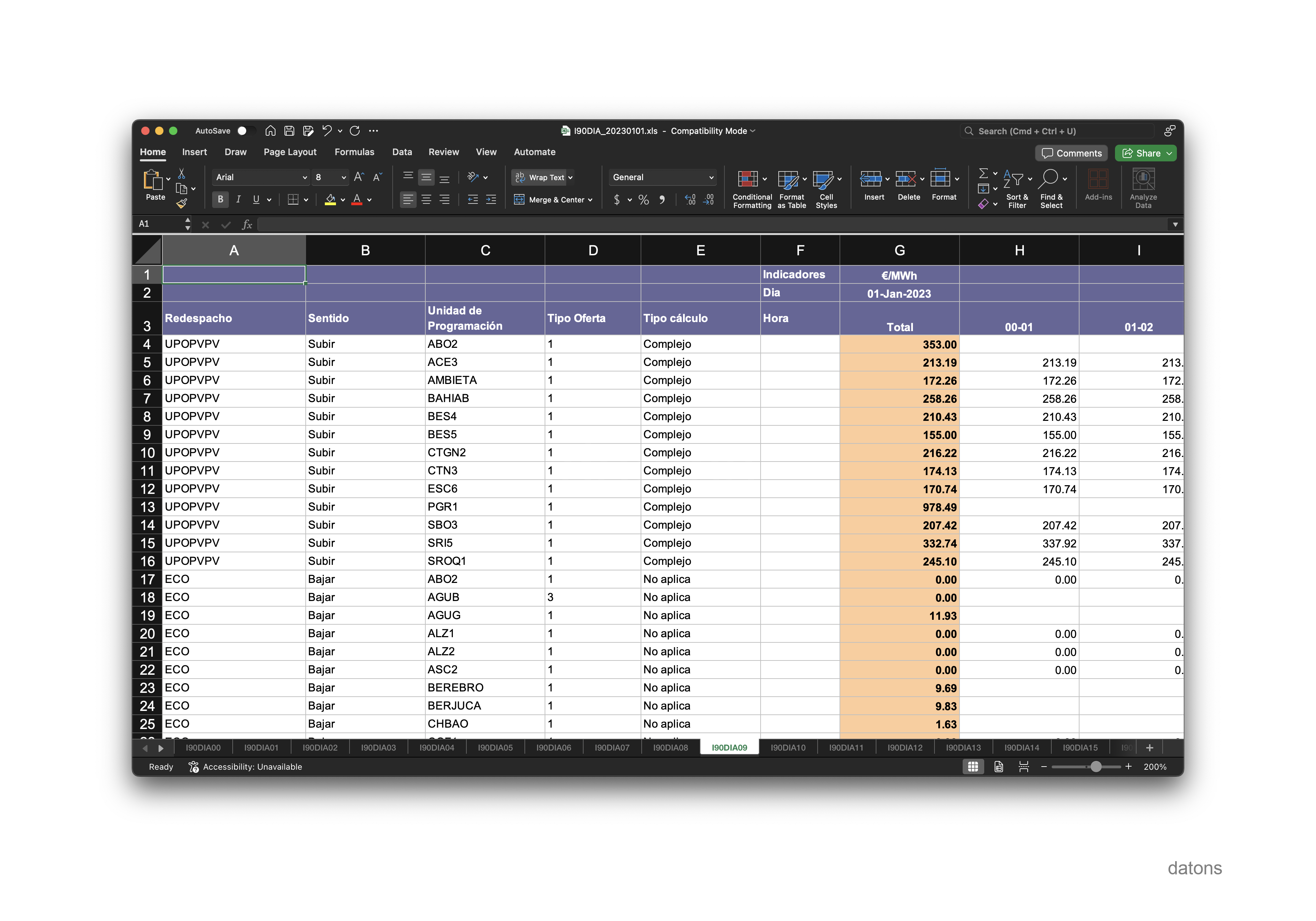
Si quisiéramos mirar el precio, en €/MWh, que cobrarían las unidades por estas restricciones, tendríamos que irnos a la hoja I90DIA09.
Utilizando el conocimiento del dominio que proporciona el Boletín Oficial del Estado sobre la operativa del sistema eléctrico en España, podemos transformar todas las hojas de Excel en una sola tabla que contenga la información clasificada de la siguiente manera:
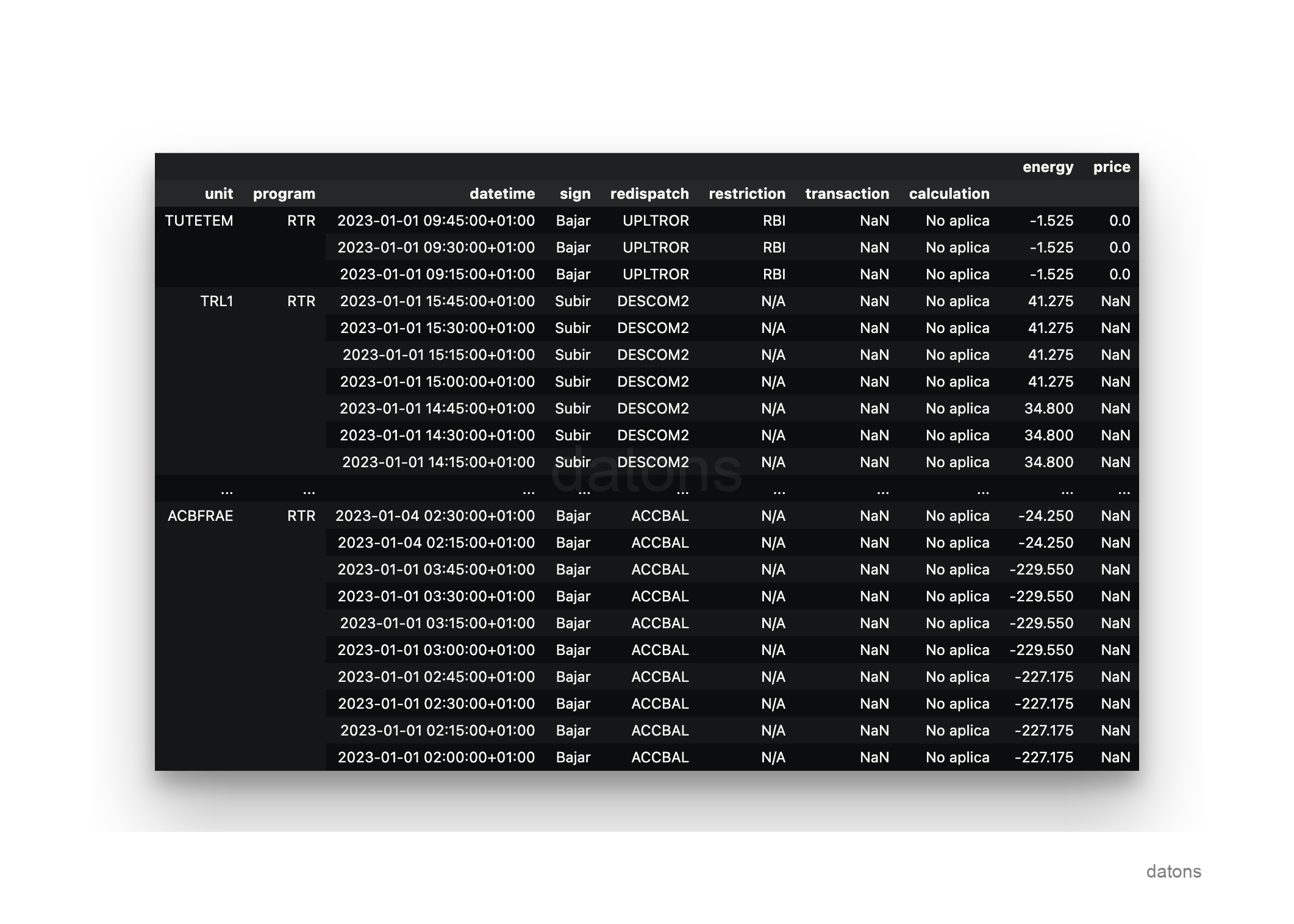
Cada registro representa una unidad de programación en un programa de generación, que ha sido ajustada de una determinada manera por los operadores de mercado y sistema, OMIE y REE, respectivamente, para generar, o no, una cantidad de energía a un precio concreto.
Diseñar esquema de la DB
Una vez estructuradas las relaciones entre las tablas, podemos definir el esquema de la DB siguiendo el modelo relacional y aplicando técnicas como la normalización para evitar la repetición de información. Por ejemplo, las unidades de programación tienen una tecnología asociada, que puede ser hidráulica, eólica, solar, etc.
Para evitar duplicar la información del tipo de tecnología en la tabla de datos operacionales, creamos una tabla específica para las unidades de programación. Esta tabla contendrá la información de cada unidad de programación y su tecnología asociada, separada de la tabla de datos operacionales.
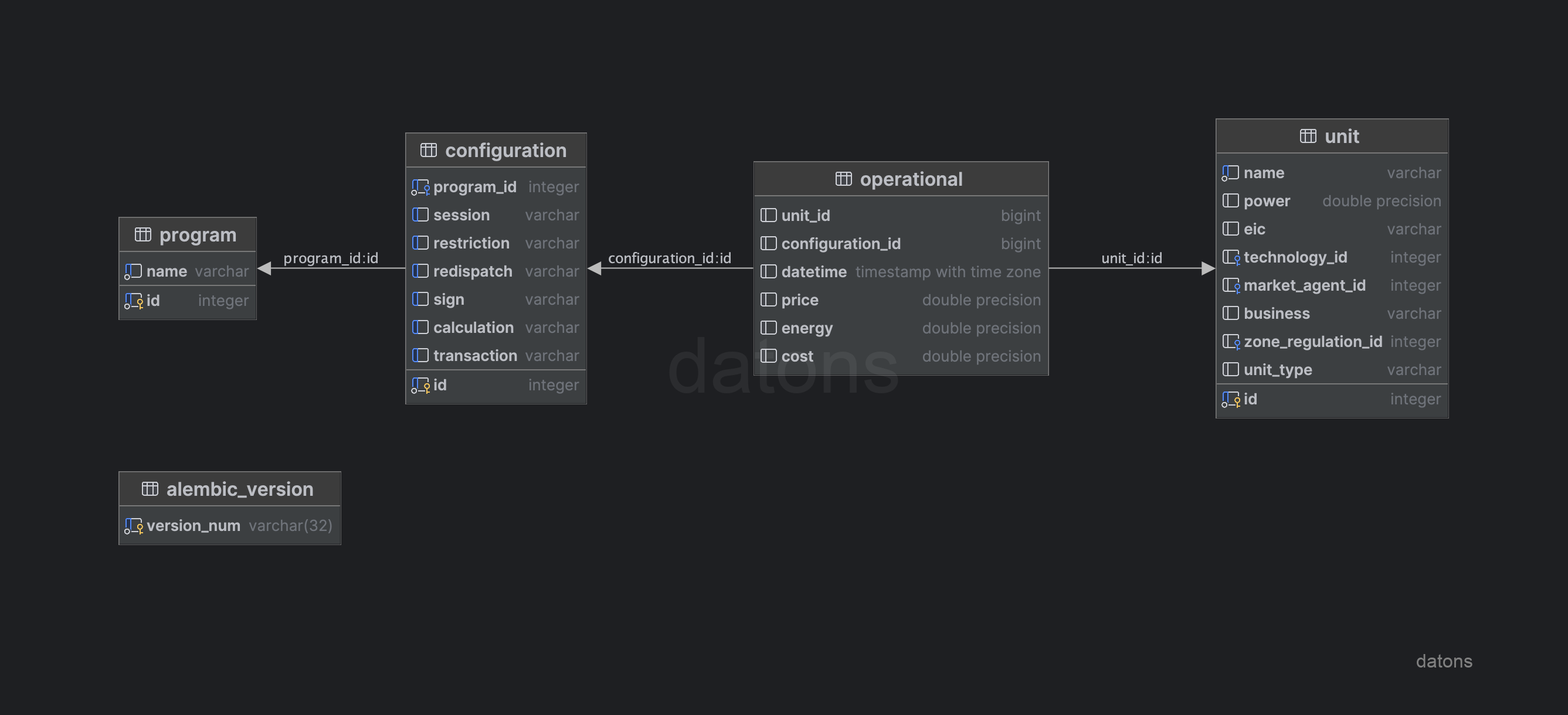
unit: información de las unidades de programación, como la tecnología que emplean para generar energía.configuration: configuración de los programas de generación, como el tipo de restricción que se aplica.program: información de los programas de generación.operational: información operacional de las unidades de programación (energía y precio según programa, unidad y condiciones operativas).
Alquilar DB
Una vez diseñado el esquema de la DB, podemos alquilar una DB en la nube para conectarnos a ella desde cualquier cliente (Python, Excel, Power BI, etc.)
En nuestro caso, hemos alquilado una DB PostgreSQL por $15 al mes en Digital Ocean. Al principio, no es recomendable sobrealquilar recursos (memoria, CPU, etc.) para no gastar dinero en cosas que no necesitamos. En caso de que necesitemos más recursos, podemos escalar la DB en cuestión con un click.
Una vez creada la DB, nos proporcionan las credenciales que utilizaremos luego para conectarnos a ella.
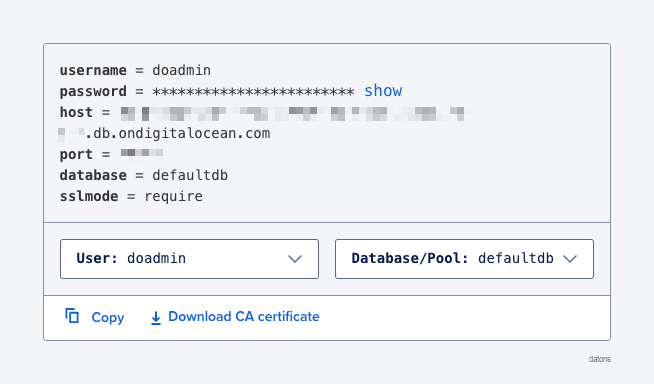
Crear tablas en DB
Para crear las tablas en la DB, primero debemos definir el esquema de las tablas sobre un archivo. En nuestro caso, hemos definido el esquema sobre un archivo models.py que contiene la estructura de las tablas, con las columnas y tipos de datos.
Ahora creamos la conexión a la DB con las credenciales que nos proporcionó Digital Ocean.
from sqlalchemy import create_engine
engine = create_engine(f'postgresql://{USER}:{PASSWORD}@{URL}:{PORT}/{DATABASENAME}')Finalmente, creamos las tablas desde Python.
from models import Base
Base.metadata.create_all(engine)Todo bien hasta aquí, pero las tablas están vacías. ¿Cómo insertamos los datos?¿Cómo los consultamos?
Interactuar con DB
Insertar registros en DB
Al estructurar la información en diferentes tablas para no repetir la información, debemos segmentar el Excel normalizado en diferentes archivos para insertarlos en las tablas correspondientes de la DB.
Por tanto, segmentamos el Excel normalizado en diferentes tablas y las exportamos a nuevos archivos Excel.
segment_table(entity='unit').to_excel('unit.xlsx')
segment_table(entity='program').to_excel('program.xlsx')
...
segment_table(entity='operational').to_excel('operational.xlsx')De nuevo, con Python, podemos insertar los datos en la DB directamente desde los archivos Excel, utilizando la librería de pandas.
import pandas as pd
df = pd.read_excel('unit.xlsx')
df.to_sql('unit', engine)
df = pd.read_excel('program.xlsx')
df.to_sql('program', engine)
...
df = pd.read_excel('operational.xlsx')
df.to_sql('operational', engine)No hacía falta exportar los datos a Excel porque ya los teníamos en Python. Sin embargo, es buena práctica separar los procesos para evitar, en un futuro, que se mezclen los datos si utilizamos el mismo código.
Solicitar datos desde la DB
Ya podemos solicitar los datos desde la DB. Por ejemplo, veamos los datos de algunas unidades de programación de Iberdrola que contienen IBEG en su nombre.
SELECT *
FROM unit
WHERE name LIKE '%IBEG%'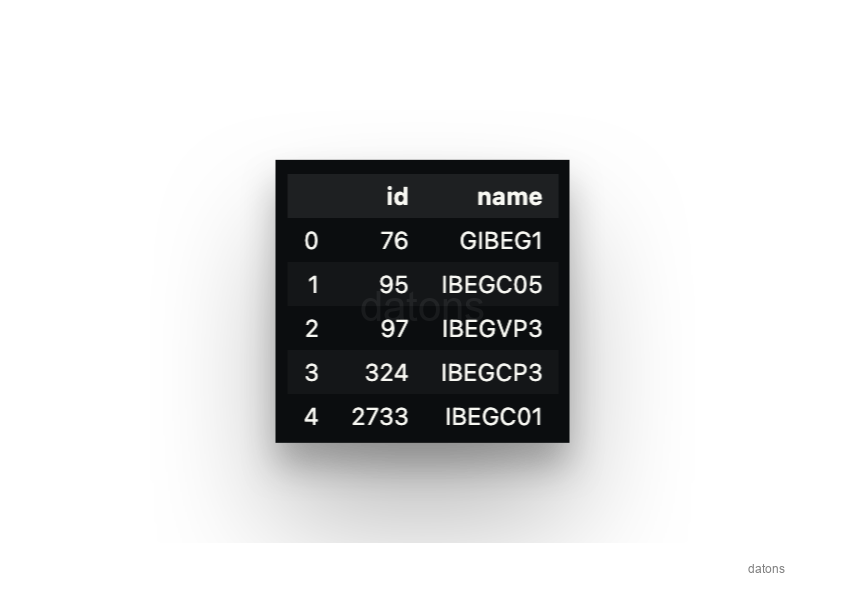
De momento, la base de datos es muy pobre porque tiene la información justa para relacionar los datos operacionales de las unidades de programación con los programas de generación. Si queremos agregar la información según el tipo de tecnología, debemos extender el esquema de la DB.
Extender esquema de la DB
La información de las unidades de programación como la tecnología, o el sujeto de mercado que la gestiona, está en la página web de REE.
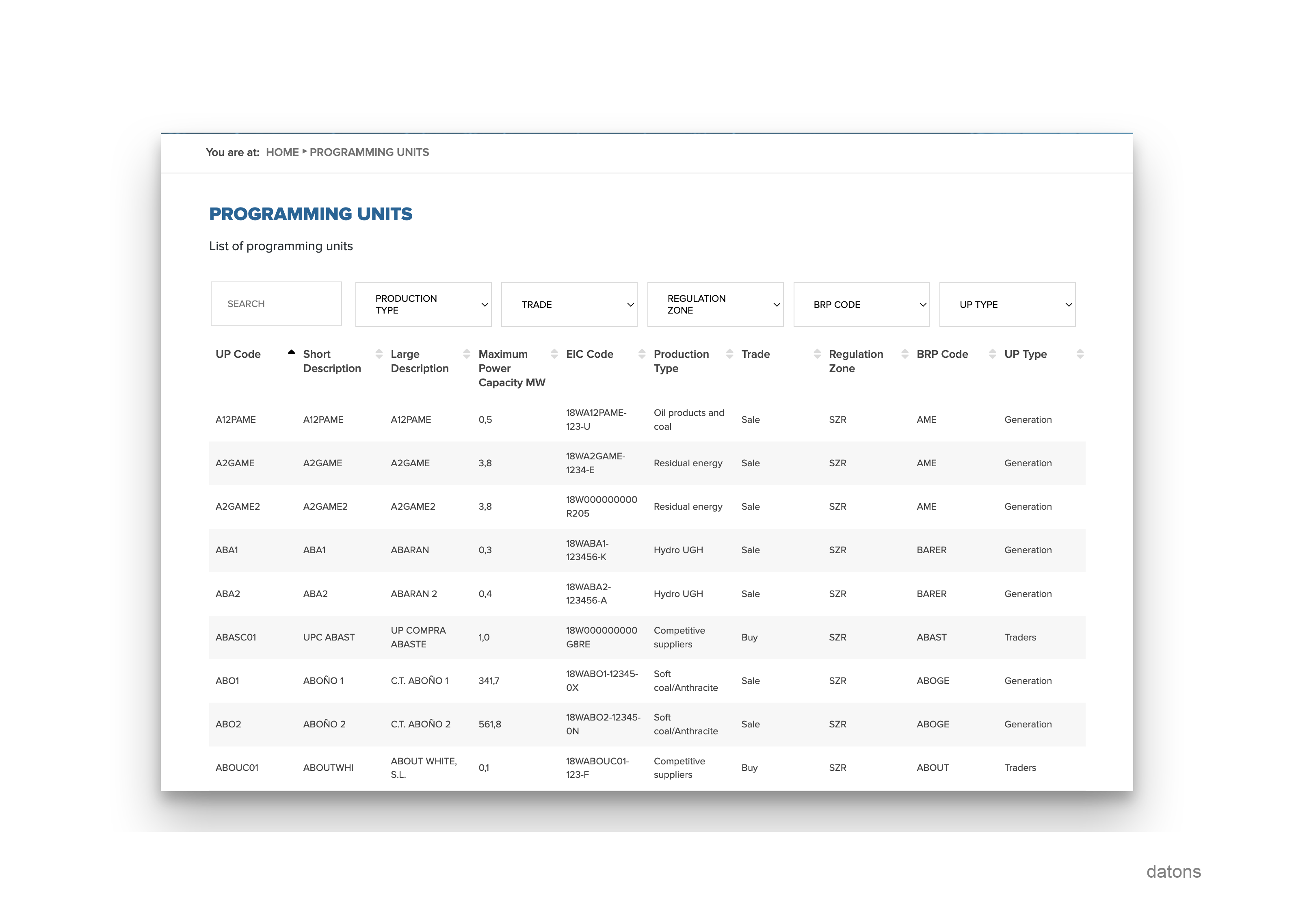
Para insertar esta información en la base de datos, primero extendemos el esquema de la tabla units con las nuevas columnas en models.py y actualizamos la DB.
Base.metadata.create_all(engine)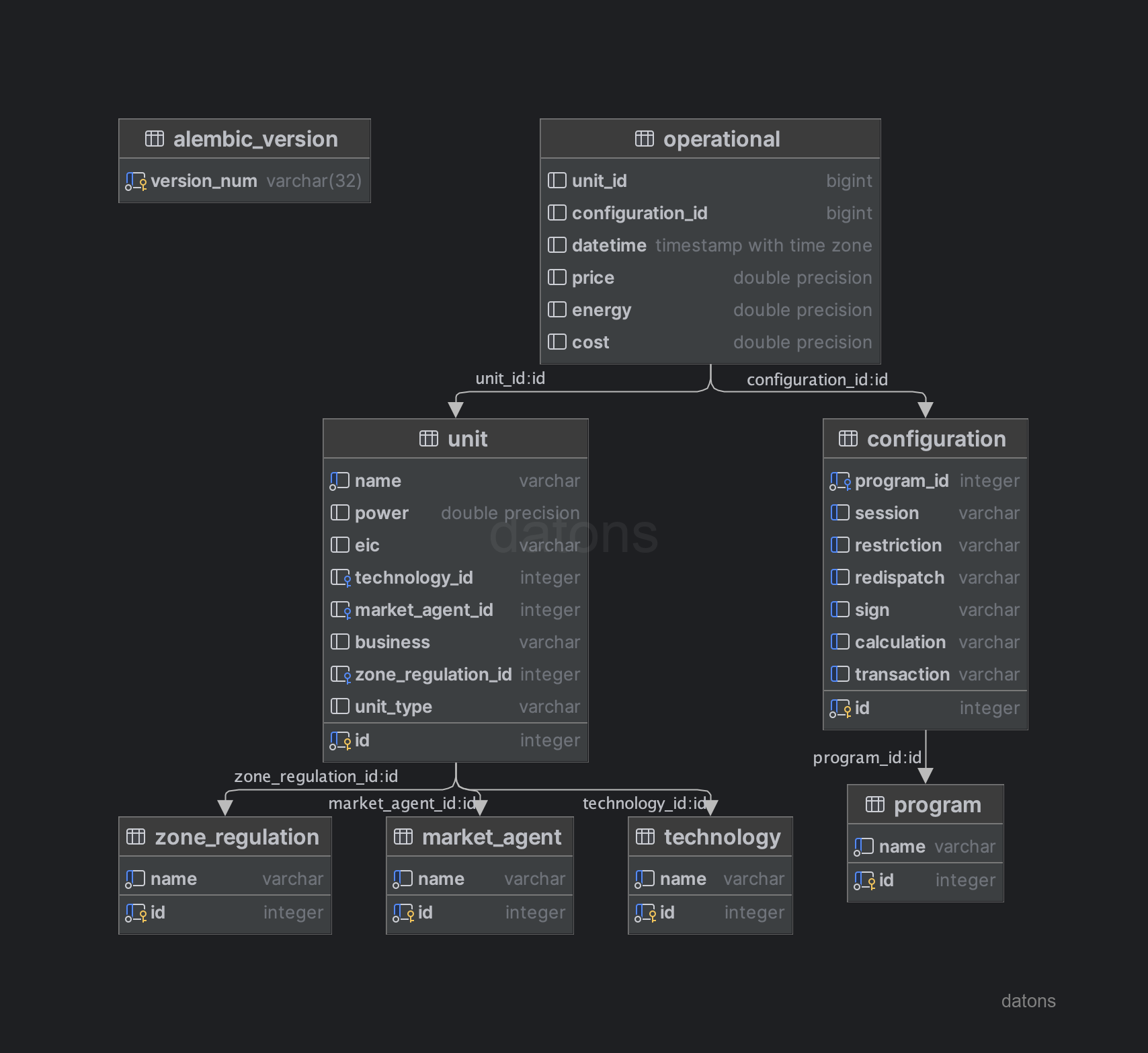
Descargamos los datos de la página web de REE, los preprocesamos acorde al esquema de la DB y los insertamos en la misma.
df = pd.read_excel('units_ree_I90.xlsx')
df.to_sql('unit', engine, if_exists='replace')Ahora, no solo tendremos más información sobre las unidades de programación, sino que también podremos solicitar la información de las unidades de programación según el sujeto de mercado. Por ejemplo, veamos qué unidades de programación están gestionadas por el sujeto de mercado IBEG, pertenecientes a Iberdrola.
SELECT *
FROM unit
INNER JOIN market_agent
ON unit.market_agent = market_agent.id
WHERE market_agent.name = 'IBEG'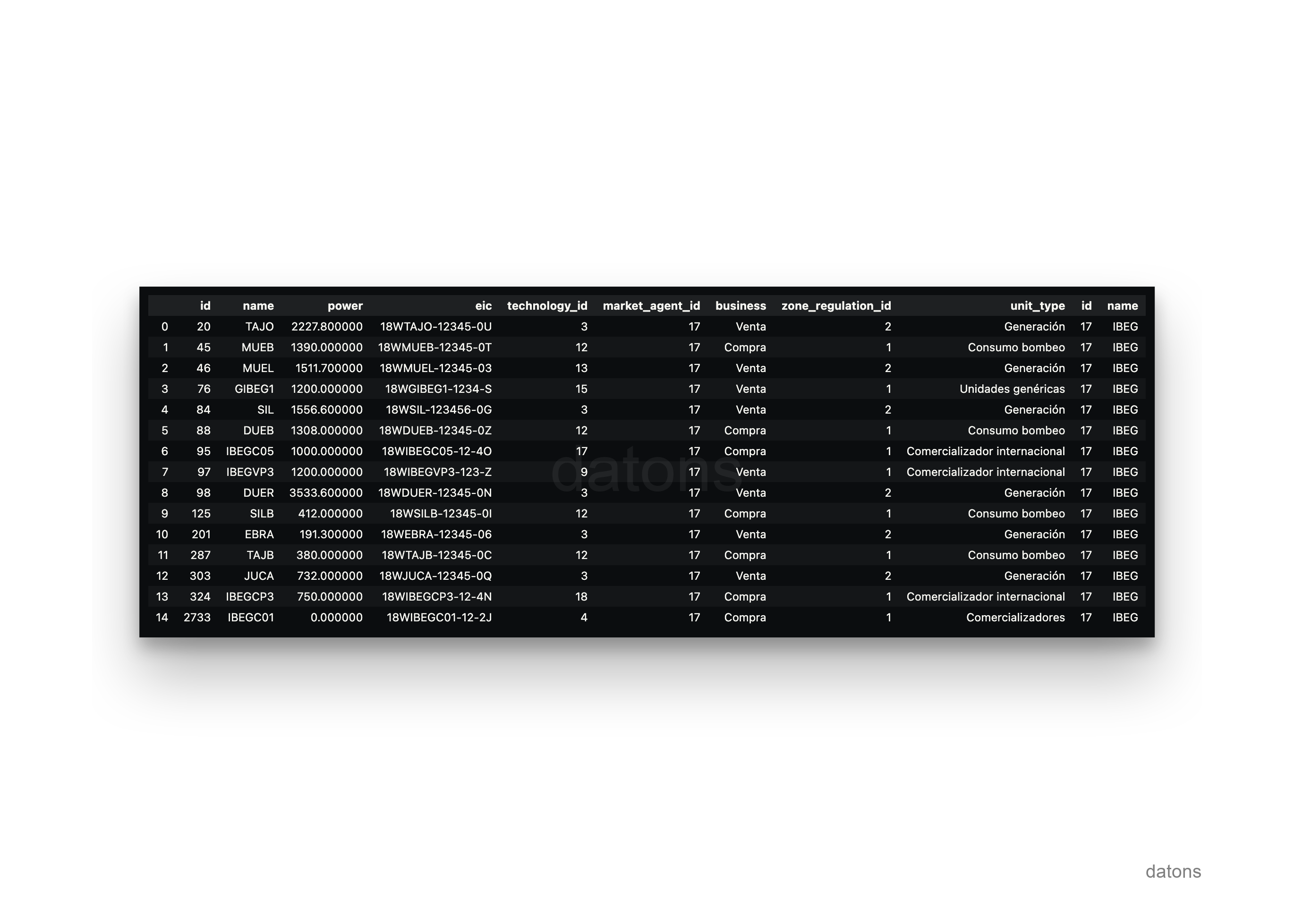
También podemos utilizar el sujeto de mercado para solicitar la información operacional de las unidades de programación.
SELECT
unit.name AS unit_name,
program.name AS program_name,
operational.*,
configuration.*
FROM operational
INNER JOIN unit
ON operational.unit_id = unit.id
INNER JOIN market_agent
ON unit.market_agent_id = market_agent.id
INNER JOIN configuration
ON operational.configuration_id = configuration.id
INNER JOIN program
ON configuration.program_id = program.id
WHERE market_agent.name = 'IBEG'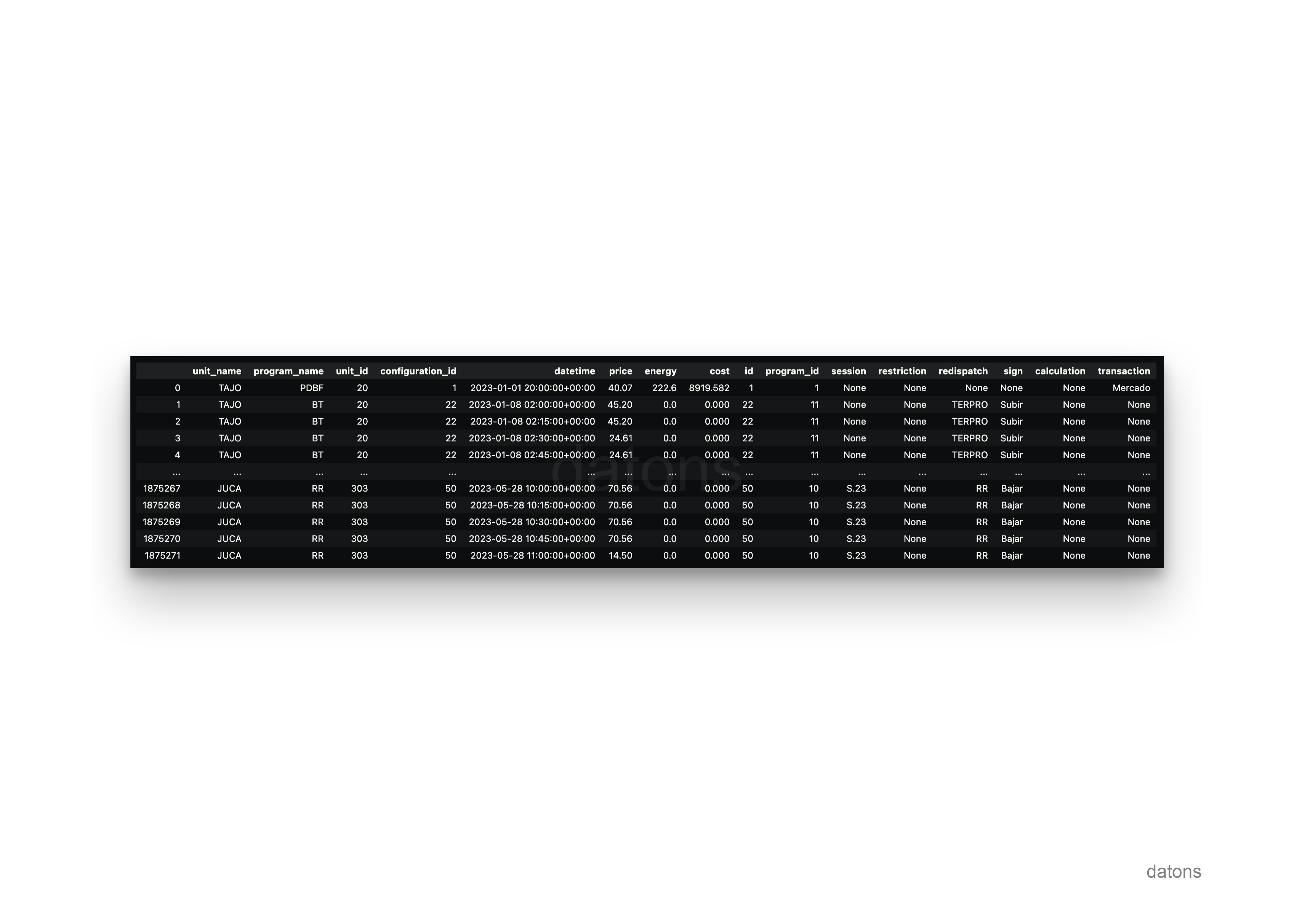
Compartir acceso a DB
Si trabajas en equipo, necesitarás compartir la información con ellos. ¿Cómo les puedes dar acceso a la información?
Credenciales
Pasándole las credenciales de la DB e indicándoles cómo acceder a través de un cliente SQL, como Python.
from sqlalchemy import create_engine
engine = create_engine(f'postgresql://{USER}:{PASSWORD}@{URL}:{PORT}/{DATABASENAME}')Consultar DB con Pandas en Python
Así como consultar la DB con la librería pandas: defines la query y ejecutas con la función pd.read_sql, conectándote a la DB con engine.
query = """
SELECT
*
FROM
unit
WHERE
market_agent = 'IBEG'
"""
pd.read_sql(query, engine)¿Qué pasa si mis compañeros no manejan Python?
Otros programas para consultar DB
La DB está alojada en una URL a la que puede acceder cualquier persona con las credenciales. Por tanto, existen multitud de programas que, dadas las credenciales, pueden conectarse a la DB y ejecutar consultas. A continuación te muestro algunos ejemplos.
Mejoras
Como toda empresa, no todo el mundo puede acceder a la base de datos. Por tanto, necesitamos proteger la información y asegurar que solo los usuarios autorizados puedan acceder a ella. A continuación te muestro algunas de las mejoras que podemos aplicar.
- Gestión de usuarios y permisos
- Conexión restringida a través de VPN
- Ejecución continua para actualizar la DB
- API para consultar datos sin necesidad de conocer SQL
- Gestión de migraciones al modificar esquema DB
- Optimización de esquema para consultas más rápidas
- Manipular DataFrame con librerías más rápidas
Con la programación, todo es posible. Tan solo necesitas un partner tecnológico que te ayude a desarrollar tu sistema personalizado.
Conclusiones
- Acceso centralizado y actualizado: Toda la información histórica de REE está en un solo lugar, eliminando la necesidad de enviar Excels por correo que se pierden o quedan desactualizados.
- Velocidad y eficiencia: Las consultas se realizan en segundos, incluso para grandes volúmenes de datos, sin depender de procesos manuales.
- Integración con herramientas avanzadas: Compatible con Python, Power BI, Tableau, y otras herramientas, permitiendo análisis, visualización, machine learning e inteligencia artificial.
- Colaboración centralizada: Facilita el trabajo en equipo al garantizar acceso uniforme y seguro a la información, sin problemas de duplicación o versiones desincronizadas.
- Automatización y reducción de errores: Automatiza tareas repetitivas como limpieza, normalización e inserción de datos, optimizando tiempo y minimizando errores humanos.
- Escalabilidad y flexibilidad: El sistema crece con las necesidades del negocio, permitiendo ampliar recursos sin interrupciones o limitaciones.
- Preparación para análisis avanzados: Ofrece una estructura ideal para implementar técnicas predictivas y algoritmos avanzados, ayudando en la toma de decisiones estratégicas.